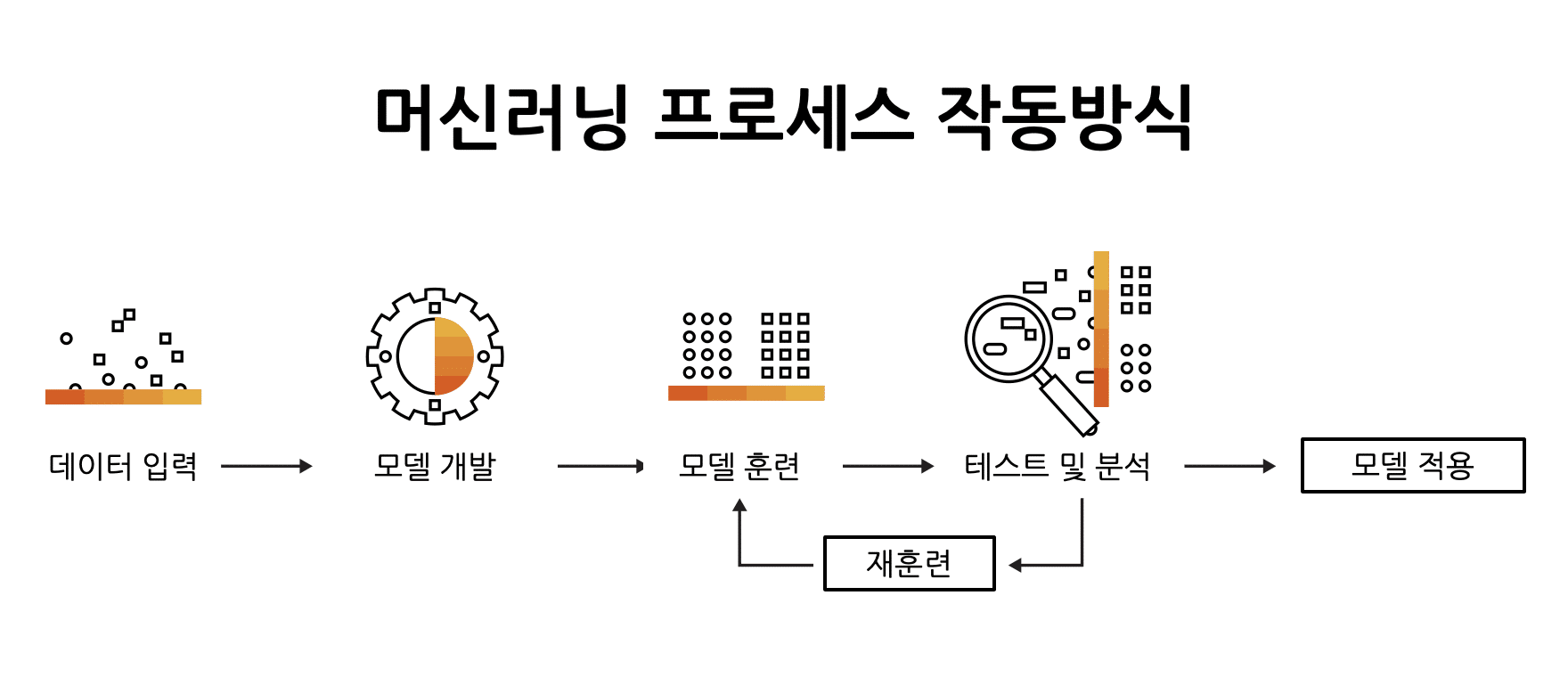
딥러닝을 공부하다 보면 반드시 마주치는 개념 중 하나가 바로 "활성화 함수(Activation Function)"입니다.
입력값에 가중치를 곱하고, 편향을 더한 후, 그냥 바로 다음 층으로 전달하면 되는 것 아닌가?
그렇지 않습니다.
딥러닝이 단순 선형 계산을 넘어서 복잡한 문제를 해결할 수 있게 만드는 비결이 바로 활성화 함수에 있습니다.
이번 글에서는 대표적인 활성화 함수인 Sigmoid, Tanh, ReLU를 중심으로,
각각의 차이점, 장단점, 선택 기준을 자세히 정리해보겠습니다.
1. 활성화 함수란 무엇인가?
🧠 활성화 함수는 뉴럴 네트워크 안에서 뉴런의 출력값을 결정해주는 함수입니다.
- 뉴런의 출력 결정자: 입력값 × 가중치 + 편향 → 활성화 함수 통과 → 출력값 생성
- 비선형성 도입: 이 함수 덕분에 신경망은 단순한 계산기에서 벗어나 복잡한 문제를 해결하는 뇌처럼 작동할 수 있습니다.
즉 입력값 × 가중치 + 편향 계산이 끝난 뒤, 이 결과를 그대로 다음 뉴런으로 보내는 것이 아니라, 활성화 함수를 거쳐 비선형성(non-linearity)을 부여한 뒤 전달합니다.
2. 왜 비선형성이 중요한가?
| 왜 비선형 함수가 필요한가? 딥러닝은 여러 층(layer)의 뉴런이 데이터를 계층적으로 처리하는 구조입니다. 그런데 각 층에서 **선형 함수(예: y = ax + b)**만 사용하면? 아무리 층을 많이 쌓아도 결국에는 하나의 선형 함수로 뭉쳐져버립니다. 👉 즉, 아무리 복잡한 구조라도 복잡한 문제는 절대 풀 수 없게 되는 것이죠. 비선형 함수, 즉 활성화 함수가 들어감으로써
|
3. 대표적인 활성화 함수 종류
Sigmoid 함수



✔ 특징
|
❗ 단점
|
Tanh 함수 (Hyperbolic Tangent)


✔ 특징
|
❗ 단점
|
사용 예시: RNN(순환 신경망), 시간 기반 데이터
ReLU 함수 (Rectified Linear Unit)



✔ 특징
|
❗ 단점
|
사용 예시: CNN, DNN 대부분의 심층 네트워크
Softmax 함수


특징
|
사용 예시: “고양이 / 개 / 토끼”처럼 3개 이상 클래스 분류 문제
4. 활성화 함수 선택 기준
| 문제 유형 | 추천 활성화 함수 | 이유 |
| 회귀 문제 출력층 | 없음 or 선형 함수 | 그대로 수치 예측 |
| 이진 분류 출력층 | Sigmoid | 확률(0~1)로 표현 |
| 다중 분류 출력층 | Softmax | 각 클래스 확률 계산 |
| 일반적인 은닉층 | ReLU / Leaky ReLU | 빠르고 효율적 |
| 순환 신경망(RNN 등) | Tanh | 시간 기반 데이터 학습 적합 |
5. 실제 사용 사례로 이해해 보기
📷 이미지 인식 (CNN)
→ ReLU 함수가 기본적으로 사용됨. 빠르고 연산량이 많아도 효율적
🌀 순환 신경망 (RNN)
→ Tanh 함수가 시간 흐름을 잘 표현하고, 상태 유지에 적합
📊 고양이 vs 강아지 이진 분류
→ 출력층에 Sigmoid 함수로 확률 계산
📚 다중 클래스 텍스트 분류
→ Softmax로 각 분류별 확률 계산
6. 핵심 용어 정리표
| 용어 | 정의 |
| 활성화 함수 | 입력값을 비선형적으로 변환하여 출력값을 만드는 함수 |
| 비선형성 | 직선이 아닌 곡선적 관계를 학습할 수 있는 능력 |
| Sigmoid 함수 | 0~1 사이 출력, 이진 분류에 적합 |
| Tanh 함수 | -1~1 출력, 중심이 0으로 수렴 속도 빠름 |
| ReLU 함수 | 0보다 작으면 0, 크면 그대로 출력, 기본 함수 |
| Softmax 함수 | 다중 분류에서 각 클래스 확률 계산 |
마무리 정리
- 활성화 함수는 뉴럴 네트워크의 ‘지능’에 해당하는 핵심 구성 요소입니다.
- 단순 선형 모델이 아닌, 복잡하고 다양한 문제를 해결할 수 있게 만들어줍니다.
- 학습 속도, 안정성, 문제 유형에 따라 적절한 함수를 선택하는 것이 중요합니다.
- 꼭 외우기보다는 직관과 예시를 통해 감을 잡아두면, 추후 모델 설계나 튜닝에서 매우 큰 도움이 됩니다.
다음 시간에는 손실함수에 대해 알아보겠습니다.
https://jdcyber.tistory.com/99
딥러닝 손실 함수 (MSE와 Cross-Entropy) 차이
딥러닝 모델은 데이터를 입력받아 어떤 결과를 예측합니다.그런데 이 예측이 정답과 얼마나 차이 나는지는 어떻게 판단할까요?바로 손실 함수(Loss Function)가 그 역할을 합니다.손실 함수는 모델
jdcyber.tistory.com
https://jdcyber.tistory.com/100
딥러닝은 어떻게 학습할까? 순전파부터 NPU까지 한눈에 정리
이번 글에서는 딥러닝이 실제로 어떤 방식으로 작동하는지,그리고 왜 AI 전용 하드웨어인 NPU가 필요하게 되었는지까지를하나의 흐름으로 이해하고 싶은 분들을 위한 정리글입니다.https://jdcyber.
jdcyber.tistory.com
궁금하신 사항은 댓글에 남겨주세요
댓글에 남겨주신 내용은
추후 정리해서 올려드리겠습니다
구독하시면 업로드 시 알려드릴게요!
-
조금이라도 도움이 되셨다면
공감&댓글 부탁드리겠습니다
감사합니다!
'NPU' 카테고리의 다른 글
| 딥러닝은 어떻게 학습할까? 순전파부터 NPU까지 한눈에 정리 (0) | 2025.04.09 |
|---|---|
| 딥러닝 손실 함수 (MSE와 Cross-Entropy) 차이 (0) | 2025.04.09 |
| 뉴럴 네트워크란 무엇인가? (NPU 개념 공부) (1) | 2025.04.09 |
| 인공지능, 머신러닝(ML), 딥러닝(DL)의 관계 (2) | 2025.04.04 |
| NPU에 흥미를 느낀 30대 비전공자의 공부 로드맵 (2) | 2025.04.04 |