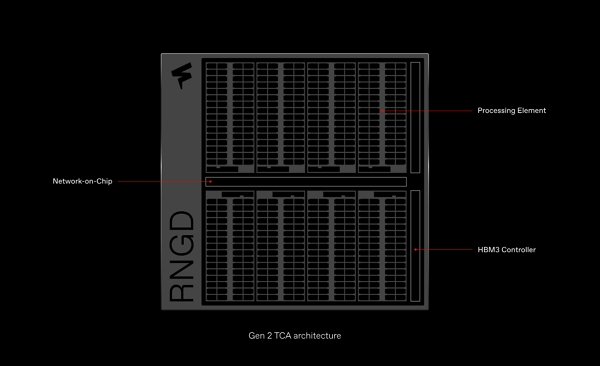
1. 들어가며
앞서 1~5편 시리즈에서는 딥러닝의 기초 개념부터 학습 및 추론 흐름까지 차근차근 살펴보았습니다:
- AI·ML·DL의 관계 이해 (1편) – 인공지능 전반과 머신러닝, 딥러닝의 위계 및 상호작용을 정리하여, 왜 딥러닝이 주목받는지를 알게 되었습니다.
- 뉴럴 네트워크 기본 구조 (2편) – 퍼셉트론에서 다층 신경망까지, 신경망이 어떻게 입력을 받아 출력을 생성하는지 이해했습니다.
- 활성화 함수의 역할 (3편) – 비선형성을 부여하는 주요 함수들을 비교하며, 모델 성능에 미치는 영향을 체감했습니다.
- 손실 함수의 개념 (4편) – 학습 목표를 정의하고 최적화를 유도하는 손실 함수의 작동 원리와 종류를 살펴보았습니다.
- 딥러닝 학습 흐름과 NPU 연관성 (5편) – 학습 단계와 추론 단계에서 NPU의 필요성을 짚어보고, 딥러닝 워크플로우 전체를 조망했습니다.
| 이제까지 배운 내용은 ‘무엇을 배우고’, ‘어떤 계산이 필요한지’를 이해하는 데 중요한 밑그림을 살펴봤습니다. 이제는 실제 NPU는 이 밑그림 위에 올라가는 ‘하드웨어 설계’ 부분을 살펴볼겁니다. 따라서 NPU 내부가 어떻게 구성되어 있는지, 그리고 데이터가 어떤 경로로 흐르는지를 알아야 비로소 전력·성능·지연 간의 트레이드오프를 이해할 수 있습니다. 앞으로 다룰 4대 핵심 컴포넌트(MAC 어레이, 온칩 메모리, DMA 엔진, 컨트롤 유닛)를 차근차근 살펴보면, 전공 배경이 없더라도 ‘왜 이런 구조가 필요한지’ 분명히 이해할 수 있을것입니다. |
자, 이제부터 본격적으로 NPU 아키텍처의 심장부로 들어가 보겠습니다!
2. NPU의 4대 핵심 컴포넌트
이제 본격적으로 NPU 안을 들여다볼 차례예요. NPU는 딥러닝 연산에 딱 맞춰 만들어진 하드웨어인데, 크게 네 가지 핵심 부분으로 나뉩니다.
MAC 어레이 (Multiply-Accumulate Array)
| 역할 : 행렬 곱셈(Multiply)과 누산(Accumulate) 연산을 동시에 수행합니다. 딥러닝의 핵심 연산인 가중치와 입력값의 곱을 더해 출력값을 만드는 역할을 하죠 왜 중요한가 : 딥러닝 모델의 대부분 연산량이 이 곱셈·누산에 집중됩니다. MAC 어레이가 넓을수록 더 많은 연산을 병렬 처리해 속도가 기하급수적으로 빨라집니다. 성능 영향 요소: 어레이 크기 (ex. 64x64 vs 256x256) 정밀도 지원(INT8, FP16 등) 비유: 공장 생산 라인에서 동시 조립 공정이 여러 개 있을 때처럼, MAC 유닛이 많으면 많을수록 한 번에 더 많은 제품(연산)을 완성할 수 있는 셈입니다. |
온칩 메모리 (On-Chip SRAM/DRAM)
| 역할 : 연산에 필요한 가중치(weight), 입력(input), 중간 결과(intermediate output) 등을 저장하는 메모리입니다. 특징 : 외부 메모리 왕복 없이 즉시 데이터를 읽고 쓸 수 있어, 지연(latency)을 크게 줄이고 전력도 아낄 수 있습니다. CPU처럼 외부 DRAM을 반복 접근하지 않기 때문에 전력 소모 및 지연 최소화 지역성(locality)에 최적화된 캐시 및 버퍼 설계 적용 비유: 주방에서 바로 손 닿는 선반에 재료를 두는 것처럼, 자주 쓰는 데이터를 가까이에 두면 요리(연산)를 빠르게 할 수 있죠 |
DMA 엔진 (Direct Memory Access Engine)
| 역할: CPU 개입 없이 메모리 간 대용량 데이터 전송을 자동으로 처리합니다. 특징 : MAC 유닛이 연산 대기 없이 연속으로 동작하려면 지속적으로 데이터가 공급되어야 합니다. DMA 엔진이 이를 관리해 연산 효율을 극대화합니다. 데이터 병목 현상을 줄여 MAC 어레이가 쉬지 않고 작동 가능하도록 보장 프리패칭(prefetching) 및 스트리밍 접근 방식으로 최적화 비유: 오케스트라에서 지휘자 없이 악기들끼리 자동으로 악보를 따라 연주하도록 미리 세팅해 두는 것처럼, DMA는 데이터 흐름을 자동으로 조율합니다. |
컨트롤 유닛 & 레지스터 파일
| 역할 : 컴파일러가 만든 명령어를 해석해 하드웨어 각 요소에 전달하고, 연산 순서와 흐름을 제어합니다. 레지스터 파일은 짧은 시간 동안 자주 쓰는 데이터를 저장합니다. 특징 : 복잡한 연산 그래프를 효율적으로 실행하려면 정확한 순서 제어와 상태 관리가 필수입니다. 컨트롤 유닛이 이를 총괄하고, 레지스터 파일이 빠른 임시 저장 공간을 제공합니다. 연산 그래프 기반 실행 순서 제어 반복문, 분기문 등 제어 흐름을 해석하여 병렬성과 동기화를 조율 비유: 공장 관리자와 작업 대장처럼, 작업 순서를 지시하고 필요한 도구를 바로 꺼낼 수 있도록 배치해두는 역할을 합니다. |
3. 데이터 흐름 파이프라인
NPU 안에서 데이터가 어떻게 이동하는지도 한눈에 보면 이해가 쉬워요. 다음 다섯 단계로 정리해 볼게요:
- 1) 명령어 디스패치: 컨트롤 유닛이 컴파일러가 만든 연산 그래프 명령어를 순서대로 가져옵니다.
- 2) 데이터 프리페치: DMA 엔진이 필요한 입력과 가중치를 외부 메모리에서 미리 온칩 메모리로 불러옵니다.
- 3) MAC 수행: MAC 어레이가 왕창 모인 유닛으로 병렬 행렬 곱셈과 누산 연산을 처리합니다.
- 4) 중간 연산: 활성화 함수나 정규화, 양자화 같은 비선형 연산을 전용 유닛에서 수행합니다.
- 5) 결과 스토어: 연산된 결과를 온칩 메모리나 호스트 메모리로 다시 저장합니다.
💡 이 과정들이 파이프라인처럼 겹겹이 연결되어, 데이터가 멈추지 않고 흐르도록 설계돼 있답니다.
4. 주요 설계 기법과 최적화 포인트
여기서 잠깐!
NPU는 단순히 빠른 연산만이 목적이 아닙니다.
전력 효율, 면적, 발열까지 고려한 정교한 설계가 필요합니다.
NPU 성능을 더 끌어올리는 대표적인 설계 기법들도 알아볼게요
- 스트라이드 접근(Striping)
데이터를 작은 블록으로 쪼개 MAC 어레이 전반에 골고루 분배해요. 병목 없이 구석구석 연산을 잘 활용할 수 있죠. - 스파스 매트릭스 가속
희소(sparse) 행렬, 즉 0이 많은 가중치는 인덱스 기반 연산으로 처리해 불필요한 계산을 줄입니다. - 파이프라인 딜레이 숨김
DMA 전송과 MAC 연산을 동시에 돌려, 데이터 전송 대기 시간을 연산 시간에 묻어버리는 트릭이에요. - 양자화 정밀도 조정
INT8, INT4 같은 저정밀 연산을 활용해 연산량·메모리 사용량을 뚝! 그러나 정확도 손실은 최소화하도록 세심하게 튜닝합니다.
5. 모바일 NPU vs. 서버 NPU 비교
어떤 환경에서 쓰이느냐에 따라 NPU도 조금씩 달라요. 간단히 비교해 봅시다:
| 구분 | 모바일 NPU (예: Apple Neural Engine) | 서버 NPU (예: Google TPU, FuriosaAI) |
| 목적 | 배터리 아끼며 실시간 추론 | 대규모 배치 처리, 학습 가속 |
| MAC 어레이 규모 | 수백~수천 개 유닛 | 수만~수십만 개 유닛 |
| 메모리 구성 | 온칩 SRAM 위주 | HBM + 대용량 DRAM |
| 최적화 포인트 | AR/VR, 카메라 등 사용자 경험 | 추천 시스템, 대형 모델 학습 |
🔍 요약: 모바일은 '즉시성'과 '배터리', 서버는 '대규모 처리량'이 핵심입니다. 따라서 아키텍처와 전력/성능 최적화 방향이 서로 다르게 설계됩니다.
이번 글에서는 NPU 내부의 구조적 요소와 데이터 흐름을 중심으로,
'하드웨어가 어떻게 딥러닝을 가속화하는가'를 살펴보았습니다.
이제 NPU가 단순히 연산만 빠른 칩이 아니라,
효율적인 메모리 구조와 정밀한 제어 장치를 포함한 복합적인 시스템이라는 것을 이해하셨을 것입니다.
다음 편에서는 이 구조들이 실제 어떤 응용 프로그램(예: 이미지 분류, 음성 인식, LLM 등)에서 어떻게 활용되는지,
NPU 기반의 딥러닝 워크로드 매핑 전략까지 이어서 살펴보겠습니다.
궁금하신 사항은 댓글에 남겨주세요
댓글에 남겨주신 내용은
추후 정리해서 올려드리겠습니다
구독하시면 업로드 시 알려드릴게요!
-
조금이라도 도움이 되셨다면
공감&댓글 부탁드리겠습니다
감사합니다!
'NPU' 카테고리의 다른 글
| ONNX로 변환하고 양자화까지! NPU를 위한 모델 최적화 실습 가이드 (1) | 2025.07.09 |
|---|---|
| NPU 실전 매핑 전략 – 이미지 분류부터 LLM까지 워크로드별 적용법 (2) | 2025.06.16 |
| 딥러닝 연산, 왜 GPU를 넘어서 NPU까지 필요할까? (5) | 2025.04.15 |
| 딥러닝은 어떻게 학습할까? 순전파부터 NPU까지 한눈에 정리 (0) | 2025.04.09 |
| 딥러닝 손실 함수 (MSE와 Cross-Entropy) 차이 (0) | 2025.04.09 |