이번 글에서는 딥러닝이 실제로 어떤 방식으로 작동하는지,
그리고 왜 AI 전용 하드웨어인 NPU가 필요하게 되었는지까지를
하나의 흐름으로 이해하고 싶은 분들을 위한 정리글입니다.
https://jdcyber.tistory.com/93
NPU를 위한 AI 기초 (1-1): 인공지능<Ai>, 머신러닝<ML>, 딥러닝<DL>의 관계 완전 정복
NPU 정복을 위한 로드맵 이후 두번째 글입니다.https://jdcyber.tistory.com/92 NPU에 흥미를 느낀 30대 비전공자의 공부 로드맵“NPU(Neural Processing Unit)를 공부하고 이해하고자 비전공자의 NPU 무작정 파헤
jdcyber.tistory.com
https://jdcyber.tistory.com/97
뉴럴 네트워크란 무엇인가? (NPU 개념 공부)
뉴럴 네트워크란 무엇인가?뉴럴 네트워크(Neural Network)는 인간의 뇌 구조에서 아이디어를 얻은 인공지능 모델입니다.쉽게 말해,인간의 뇌가 수많은 뉴런(신경 세포)들이 서로 연결되어 정보를 처
jdcyber.tistory.com
이제는 뉴럴 네트워크가 실제로 어떤 방식으로 입력 데이터를 받아 예측을 하고,
학습하며 스스로 개선되는지를 자세히 알아보고,
마지막으로 왜 이 모든 과정이 엄청난 연산량을 유발하는지,
그리고 그 연산을 어떻게 처리해야 하는지(NPU)까지 짚어보겠습니다.
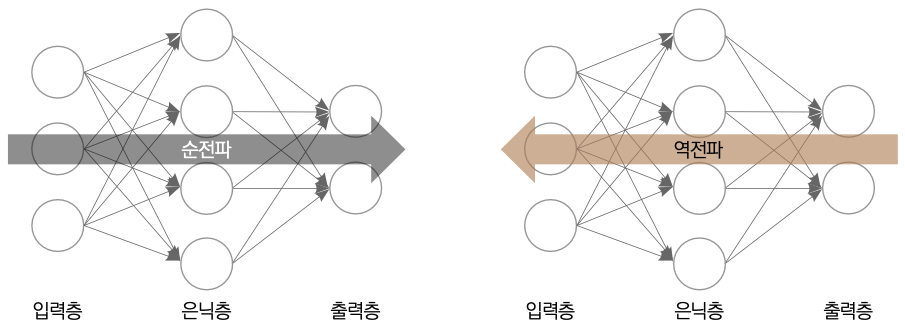
순전파(Forward Propagation): 예측의 시작
순전파란?
입력값이 뉴럴 네트워크를 ‘앞으로’ 통과하며 출력값을 생성하는 과정입니다.
예를 들어, 이미지 데이터를 입력하면
→ 신경망이 여러 층을 거치며
→ “이건 고양이다”와 같은 예측을 만들어냅니다.
구체적인 계산 흐름
각 뉴런에서 이루어지는 계산은 다음과 같습니다:
출력값 = (입력값 × 가중치) + 편향 → 활성화 함수 통과예시:
- 입력값: [0.6, 0.2, 0.9]
- 가중치: [0.8, 0.1, 0.3]
- 편향: 0.2
이 값은 활성화 함수를 거쳐 다음 층으로 전달됩니다.
- ReLU: 음수면 0, 양수면 그대로
- Sigmoid: 값을 0~1 사이로 압축 (확률로 해석 가능)
👉 활성화 함수가 궁금하다면?
https://jdcyber.tistory.com/98
NPU를 위한 AI 기초 딥러닝의 핵심, 활성화 함수 완전 정복 (ReLU, Sigmoid, Tanh 차이와 선택 기준)
딥러닝을 공부하다 보면 반드시 마주치는 개념 중 하나가 바로 "활성화 함수(Activation Function)"입니다.입력값에 가중치를 곱하고, 편향을 더한 후, 그냥 바로 다음 층으로 전달하면 되는 것 아닌가
jdcyber.tistory.com
2. 데이터를 층을 따라 전달하며 ‘특징’을 학습한다
딥러닝 신경망은 다음처럼 구성됩니다:
입력층 → 은닉층1 → 은닉층2 → ... → 출력층- 첫 층: 선, 모서리 등 단순 특징 인식
- 중간 층: 윤곽, 형태 등 중간 패턴 추출
- 마지막 층: ‘고양이냐 강아지냐’ 같은 복잡한 판단
역전파(Backpropagation): 틀린 걸 바로잡는 방식
손실 함수(Loss Function)
먼저 정답과 예측값의 차이를 수치로 계산해야 하겠죠?
이 차이를 계산하는 게 바로 손실 함수입니다.
- 예시: 정답이 1, 예측이 0.7 → 손실은 0.3
- 대표 손실 함수:
👉 손실 함수에 대해 더 알고 싶다면?
https://jdcyber.tistory.com/99
딥러닝 손실 함수 (MSE와 Cross-Entropy) 차이
딥러닝 모델은 데이터를 입력받아 어떤 결과를 예측합니다.그런데 이 예측이 정답과 얼마나 차이 나는지는 어떻게 판단할까요?바로 손실 함수(Loss Function)가 그 역할을 합니다.손실 함수는 모델
jdcyber.tistory.com
기울기(Gradient) 계산
오차를 줄이기 위해 가중치를 얼마나 바꿔야 할지 계산합니다.
이때 쓰이는 개념이 기울기(Gradient)입니다.
딥러닝 프레임워크는 자동 미분(Autograd)으로 이 계산을 자동 처리합니다.
- 기울기는 쉽게 말해 오차를 줄이기 위해 가중치를 얼마나 바꿔야 하는지 알려주는 방향과 크기입니다.
- 이 과정을 '미분'을 통해 수행하는데, 자동 미분(Autograd) 같은 기술로 프레임워크가 자동 계산합니다.
경사 하강법(Gradient Descent): 조금씩 내려가기
가중치를 한 번에 바꾸는 게 아니라,
조금씩 조금씩 오차가 줄어드는 방향으로 조정합니다.
이게 바로 경사 하강법입니다.
- 학습률(Learning Rate): 얼마나 바꿀지 결정하는 조정값
- ‘경사’를 따라 아래로 내려간다 = 오차가 점점 줄어드는 방향
4. 순전파 + 역전파 = 딥러닝의 핵심 루프
- 데이터를 넣는다 → 순전파
- 결과가 틀리다 → 손실 계산
- 어떻게 고칠까? → 역전파 + 기울기 계산
- 가중치 조정 → 학습
- 다시 순전파... 반복!
이 과정을 수백 번, 수천 번 반복하면서 모델은 점점 더 정확해지는 것입니다.
5. 왜 이 모든 연산이 NPU와 연결되는가?
연산량이 엄청나다
- 수천~수만 개 뉴런 × 레이어 × 반복 연산
- 활성화 함수, 기울기, 가중치 업데이트 수백만 번
→ 수억 번의 계산이 순식간에 일어납니다.
CPU만으로는 부족하다
| 장치 | 특징 |
| CPU | 범용 연산, 순차 처리 중심 |
| GPU | 병렬 연산 가능, 딥러닝 속도 향상 |
| NPU | AI 전용 설계, 딥러닝 연산에 특화됨 |
NPU는 딥러닝 연산에 꼭 필요한 구조만 남기고 최적화되어 있어서
→ 전력 효율도 좋고 속도도 훨씬 빠릅니다.
6. 핵심 요약 정리표
| 항목 | 의미 |
| 순전파 | 입력값으로 예측값을 생성하는 과정 |
| 역전파 | 오차를 계산해 가중치를 조정하는 과정 |
| 손실 함수 | 예측값과 실제값의 차이를 수치화 |
| 기울기/경사 하강법 | 오차를 줄이기 위한 조정 방향과 크기 계산 |
| 연산량 증가 | 수억 번의 연산이 반복적으로 발생 |
| NPU 필요성 | 이런 계산을 빠르게 처리하기 위해 등장한 AI 전용 칩 |
마무리하며
지금까지 딥러닝의 기본 작동 원리부터
‘왜 NPU가 필요한지’까지 한 흐름으로 정리해봤습니다.
이 글이 딥러닝 학습 흐름을 이해하는 데 도움이 되었다면,
이후에는 실제로 NPU가 어떻게 생겼고 어떤 구조로 돌아가는지 배워보도록 합시다.
궁금하신 사항은 댓글에 남겨주세요
댓글에 남겨주신 내용은
추후 정리해서 올려드리겠습니다
구독하시면 업로드 시 알려드릴게요!
-
조금이라도 도움이 되셨다면
공감&댓글 부탁드리겠습니다
감사합니다!
'NPU' 카테고리의 다른 글
| NPU 아키텍처 깊이 들여다보기 – 주요 컴포넌트와 데이터 흐름 (1) | 2025.05.13 |
|---|---|
| 딥러닝 연산, 왜 GPU를 넘어서 NPU까지 필요할까? (5) | 2025.04.15 |
| 딥러닝 손실 함수 (MSE와 Cross-Entropy) 차이 (0) | 2025.04.09 |
| 딥러닝의 핵심, 활성화 함수 (ReLU, Sigmoid, Tanh 차이와 선택 기준) (1) | 2025.04.09 |
| 뉴럴 네트워크란 무엇인가? (NPU 개념 공부) (1) | 2025.04.09 |